Python поддерживает работу с различными популярными форматами данных — CSV, JSON.
Работа с CSV-данными
CSV — популярный формат т.к. многие средства импорта/экспорта работают с ним. Данный формат обязан своей популярности MS Excel, которая позволяет сохранять в CSV свои таблицы. Для доступа к CSV-файлам нужно импортировать модуль csv.
Напишем программу, выводящую первые N-строк из CSV файла:
import csv
max = int(input("Сколько строк вывести из файла: "))
k = 0
with open('test.csv') as f:
f_csv = csv.reader(f)
headers = next(f_csv)
for row in f_csv:
print(row)
k = k + 1
if k == max:
break
input()В данном примере пользователь должен ввести сколько вывести строк из файла. Далее мы с помощью цикла проходим по всему файлу «test.csv» и выводим строки из этого файла. Переменная row является кортежем.
Чтобы записать CSV-данные, вы можете использовать модуль csv, но создать объект writer. Например:
Чтобы записать CSV-данные, вы можете использовать модуль csv, но создать объект writer. Например:
import csv
headers = ['Symbol', 'Price', 'Date', 'Time']
rows = [('AA', 39, '02/02/2020', '00:00'), ('BB', 36, '03/03/2020', '00:12'), ('CC', 23, '04/05/2020', '12:34')]
with open('test2.csv', 'w') as f:
f_csv = csv.writer(f)
f_csv.writerow(headers)
f_csv.writerows(rows)
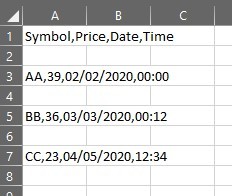
input("Файл создан!")В данном примере мы создаем файл в формате csv. Файл будет выглядеть вот так:
Работа с JSON-данными
Python также обладает поддержкой формата JSON (JavaScript Object Notation). Модуль json предоставляет простой способ кодировать и декодировать данные в JSON. Пример преобразования структуры данных Python в JSON:
import json
data = {
'name' : 'Max',
'shares' : 100,
'count' : 542.20
}
json_str = json.dumps(data)
print(json_str)
input()Если вы работаете с файлами, а не строками, вы можете использовать функции json.dump() и json.load() для кодирования и декодирования данных. Например:
import json
data = {
'name' : 'Max',
'shares' : 100,
'count' : 542.20
}
# записываем JSON-данные
with open('data.json', 'w') as f:
json.dump(data, f)
# читаем данные обратно
with open('data.json', 'r') as f:
data = json.load(f)
print(data)
input()Данный пример создаст файл «data.json», внесет в него данные и потом прочитает внесенные данные. Самостоятельно проверьте работоспособность данного кода.
JSON-кодирование поддерживает базовые типы данных — None, bool, int, float и str, а также списки, кортежи и словари, состоящие из тех базовых типов.
Работа с XML-данными
XML расшифровывается как eXtensible Markup Language — «расширяемый язык разметки».
XML — стандартизированный, но расширяемый язык текстовой разметки, основанный на удобном и легко читаемом, как пользователями, так и компьютером, синтаксисе, состоящем из тегов, атрибутов и препроцессоров.
Для извлечения данных из простого XML-документа можно использовать модуль xml.etree.ElementTree.
Напишем простую RSS-ленту:
<?xml version="1.0"?>
<rss version="2.0" xmlns:dc="http://purl.org/dc/elements/1.1/">
<channel>
<title>RSS-лента</title>
<link>https://it-black.ru</link>
<language>ru</language>
<dedication>Описание</dedication>
<item>
<title>Заголовок 1</title>
<link>Ссылка 1</link>
<dedication>Описание 1</dedication>
<pubDate>Дата 1</pubDate>
</item>
<item>
<title>Заголовок 2</title>
<link>Ссылка 2</link>
<dedication>Описание 2</dedication>
<pubDate>Дата 2</pubDate>
</item>
</channel>
</rss>Для извлечения данных из простого XML-документа можно использовать модуль xml.etree.ElementTree. Напишем сценарий, который сделает сводку произвольной RSS-ленты, содержащей элементы title, pubDate, link. Листинг:
from urllib.request import urlopen
from xml.etree.ElementTree import parse
# Загружвем RSS-ленту и парсим её
doc = parse('test.xml')
# Извлекаем и выводим интересующие теги
for item in doc.iterfind('channel/item'):
title = item.findtext('title')
date = item.findtext('pubDate')
link = item.findtext('link')
print(title)
print(date)
print(link)
input()Функция xml.etree.ElementTree.parse() парсит весь XML-документ в объект документа.
Видео по работе с форматами:
Видео по работе с форматами: